SVD for fun and profit
April 8, 2009I’m working on a recommendation system designed to suggest features to users who haven’t tried them yet, based on what other people use. The method I’m looking at now is using the Singular Value Decomposition (SVD) technique to build suggestions; it has been used in the Netflix prize, among other places.
SVD for profit: the Netflix prize ¶
The movie rental service Netflix offers recommendations to their clients, and launched a contest in 2006 to improve their recommendation engine. Participants get a dataset of 100 million ratings for 480,189 users and 17,770 movies. The matrix of all ratings is $480,189×17,770$ (over $8.5×10^9$ values), of which almost 99% is empty.
It is such a hard problem (computation-wise) that Netflix is currently offering $1 million for a 10% improvement over their existing system. My dataset is far from being as large as theirs, but is large enough to require some special attention—we can’t use naïve techniques, and can’t fit the entire matrix in memory.
Quick explanation of matrix approximations using the SVD ¶
The SVD can be used to approximate a matrix, which is useful in this kind of system.
The SVD of a $m \times n$ matrix $M$ is the collection of 3 matrices ($U$, $\Sigma$, $V$) where $U$ is an $m \times m$ matrix, $\Sigma$ an $m \times n$ diagonal matrix, and $V^{*}$ the conjugate transpose of an $n \times n$ matrix, such that $M = U \Sigma (V^{*})$.
Using an example from the Wikipedia page:
\[ \begin{bmatrix} 1 & 0 & 0 & 0 & 2 \\ 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \\ 0 & 4 & 0 & 0 & 0 \end{bmatrix} = \begin{bmatrix} 0 & 0 & 1 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & -1 \\ 1 & 0 & 0 & 0 \end{bmatrix} \times \begin{bmatrix} 4 & 0 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 & 0 \\ 0 & 0 & \sqrt{5} & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 \end{bmatrix} \times \begin{bmatrix} 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 \\ \sqrt{0.2} & 0 & 0 & 0 & \sqrt{0.8} \\ 0 & 0 & 0 & 1 & 0 \\ - \sqrt{0.8} & 0 & 0 & 0 & \sqrt{0.2} \end{bmatrix} \]
$$ M = U \times \Sigma \times V $$
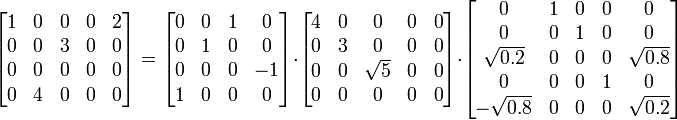
The SVD can be used to approximate a matrix: By keeping $k$ columns of $U$ as ($U_k$), $k$ values of $\Sigma$ as ($\Sigma_k$), and $k$ lines of $V^{*}$ as ($V^{*} k$), we still get $M \approx U_k \Sigma_k (V^{*}k)$. If $k$ is small enough, we can use a total number of cells lower than the original $n \times m$.
Note: Running an SVD on a matrix as large as the Netflix one requires a special technique, which reduces these billions of cells to a few millions only while retaining a lot of information. See Timely Development for an example using the Netflix dataset.
Example of matrix approximation ¶
Consider the following table of book ratings by users:
| User 1 | User 2 | User 3 | User 4 | |
|---|---|---|---|---|
| Book 1 | 1 | 4 | 1 | |
| Book 2 | 2 | 5 | ||
| Book 3 | 4 | 1 | 4 | |
| Book 4 | 1 | |||
| Book 5 | 3 | 5 | 5 | 1 |
| Book 6 | 3 | 2 |
From which we can build this original matrix:
\[ \begin{bmatrix} 1 & 4 & 0 & 1 \\ 2 & 0 & 0 & 5 \\ 0 & 4 & 1 & 4 \\ 1 & 0 & 0 & 0 \\ 3 & 5 & 5 & 1 \\ 0 & 3 & 2 & 0 \end{bmatrix} \]
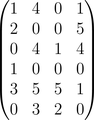
Rebuilt with $k = 4$, the matrix is the same.
Approximation in rounded integers with $k = 3$:
\[ \begin{bmatrix} 0 & 4 & 1 & 1 \\ 2 & 0 & 0 & 5 \\ 0 & 4 & 1 & 4 \\ 0 & 0 & 0 & 0 \\ 3 & 5 & 5 & 1 \\ 0 & 3 & 2 & 0 \end{bmatrix} \]
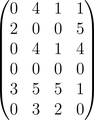
Three ratings are wrong: (User1, Book1) and (User4, Book1) were both 1 and are now 0, (User1, Book3) was 0 and is now 1.
With $k = 2$:
\[ \begin{bmatrix} 1 & 3 & 2 & 1 \\ 1 & 1 & -1 & 5 \\ 2 & 3 & 1 & 4 \\ 0 & 0 & 0 & 0 \\ 2 & 6 & 4 & 1 \\ 1 & 3 & 2 & 0 \end{bmatrix} \]
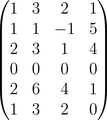
Quite a few mistakes here… one rating is -1 and one is 6! When the matrix is rebuilt, the values must always be recalibrated into the right range.
With $k = 1$:
\[ \begin{bmatrix} 1 & 3 & 2 & 2 \\ 1 & 2 & 1 & 1 \\ 1 & 4 & 2 & 2 \\ 0 & 0 & 0 & 0 \\ 2 & 5 & 3 & 3 \\ 1 & 2 & 1 & 1 \end{bmatrix} \]
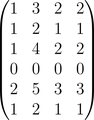
This one is way off! We can’t use such an approximation. One must then find a compromise between data size and precision by tweaking the value of $k$.
For reference, the first team to reach a RMSE under 0.8572 in their predictions on the Netflix dataset will win the prize.
SVD for fun: image compression ¶
Let’s try on real data. If we load an image as a matrix of colours, how well can we compress it using the SVD? Pretty well, even if it’s not JPEG. Take a look at “Lenna”, using different values for $k$:
$k = 1$, image generated from (1×384 + 1 + 384×1) = 769 bytes.
$k = 10$; 7,690 bytes.
$k = 20$; 15,380 bytes.
$k = 50$; 38,450 bytes.
$k = 100$; 76,900 bytes.
$k = 200$; 153,800 bytes.
Here is lenna.png, the file used as an input to the program; Please excuse the very primitive PPM writer, this is not really the point of this article.
The code for image compression is in Haskell, using the hmatrix and pngload libraries:
{kind=link}
module Main where
import Numeric.LinearAlgebra
import Codec.Image.PNG (loadPNGFile, dimensions, imageData)
import Data.Array.MArray (getElems)
import Data.Word (Word8)
import Data.Char (chr)
main = do
png <- loadPNGFile "lenna.png"
case png of
Left fail -> error fail
Right img -> do
m <- fmap (compress 10) $ mkMatrix img
savePPM "out.ppm" m
mkMatrix img = do -- creates a matrix from a PNGImage
let (w,h) = dimensions img
table <- getElems $ imageData img :: IO [Word8] -- read colours
return $ (fromEnum h><fromEnum (3*w)) $ map fromIntegral table
compress k m = u_k <> sigma_k <> v_k where
(u,sigma,v) = full svd m -- get SVD, keep:
sigma_k = (takeColumns k . takeRows k) sigma -- k values of Σ
u_k = takeColumns k u -- k columns of U
v_k = takeRows k $ trans v -- k rows of v
savePPM filename m = writeFile filename $ header ++ contents where
header = concat ["P6\n", show $ cols m `div` 3,
" ", show $ rows m, "\n255\n"]
contents = (concatMap . map) toChar $ toLists m -- format
toChar = chr . fromIntegral . round . max 0 . min 255.0 -- convert
Other techniques ¶
There are many ways to recommend items; a lot of them are described (with Python code!) in the fantastic book Programming Collective Intelligence by Toby Segaran.
See also: